Globalna awaria, padło pół internetu. Nie działają popularne aplikacje, są problemy z przelewami

Potężne problemy z dostępem do internetu dotknęły dziś użytkowników na całym świecie, w tym w Polsce. Przestały działać popularne aplikacje, strony internetowe, platformy streamingowe, a nawet systemy bankowe. Utrudnienia dotknęły m.in. mBank, PKO BP i Pocztę Polską. Skala problemów jest ogromna i dotyka kluczowych usług cyfrowych.
Padły aplikacje, streaming, banki i sklepy. Co się stało?
Poniedziałkowy poranek dla wielu firm i użytkowników indywidualnych rozpoczął się od cyfrowego chaosu. Problemy z logowaniem, niemożność załadowania stron czy błędy w działaniu aplikacji stały się powszechne, a próby odświeżania domen czy resetowania połączenia z Internetem na nic się nie zdały.
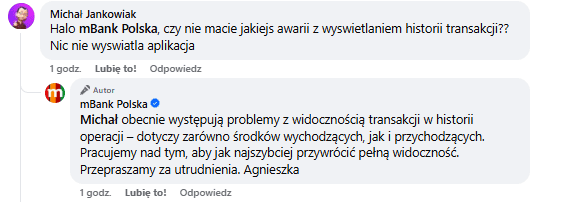
Serwis DownDetector informuje, że pierwsze problemy pojawiły się około godziny 9:00 czasu polskiego, a w kolejnych minutach liczba zgłoszeń w Polsce gwałtownie wzrastała. Klienci mBanku, PKO BP, VeloBanku i Nest Banku zgłaszali poważne utrudnienia z dostępem do bankowości internetowej i mobilnej, co uniemożliwiało realizację przelewów czy sprawdzenie salda.
Równie dotkliwe problemy odczuła Poczta Polska, której systemy monitorowania przesyłek przestały odpowiadać. To jednak tylko wierzchołek góry lodowej. zakłócenia zgłaszano również w sieciach komórkowych - m.in. w Play, Orange, T-Mobile i Plus.
Za tak rozległym paraliżem nie stoi atak hakerski ani lokalna awaria dostawcy internetu. Okazuje się, że "chmura" to nie abstrakcyjny byt, a bardzo konkretne serwery, które, jak każda technologia, bywają zawodne.
Globalna awaria sieci AWS
Utrudnienia w różnym stopniu dotknęły także gigantów e-commerce jak Allegro, Amazon czy OLX, firmy logistyczne, w tym InPost, a nawet popularne aplikacje do zamawiania jedzenia czy zakupów, jak Żabka Jush czy systemy McDonald's. Awaria uderzyła również w popularne aplikacje takie jak m.in. Snapchat, Tinder, Ring, Zoom, Slack, Tidal, Roblox, Fortnite, Duolingo, Canva, Perplexity. Dla wielu firm opierających swoją działalność na pracy zdalnej oznaczało to faktyczny przestój. Konsekwencje są natychmiastowe i bardzo kosztowne.
Dla sektora e-commerce każda minuta niedostępności sklepu to realne, liczone w milionach, straty finansowe. Dla banków to kryzys zaufania klientów, a dla firm logistycznych – chaos operacyjny. Gdy kluczowe narzędzia do komunikacji, zarządzania projektami i dostępu do danych przestają działać, praca staje się niemożliwa.
Wszystko wskazuje na to, że źródłem problemów okazał się jeden z filarów współczesnej sieci – Amazon Web Services (AWS).
Potwierdzamy zwiększoną liczbę błędów i opóźnienia w przypadku wielu usług AWS w regionie US-EAST-1. Ten problem może również dotyczyć tworzenia zgłoszeń za pośrednictwem Centrum pomocy technicznej AWS lub interfejsu API pomocy technicznej – czytamy w komunikacie Amazona dla BBC.
AWS to nic innego jak potężna platforma chmury obliczeniowej, należąca do globalnego giganta Amazon. Mówiąc prościej, AWS wynajmuje firmom z całego świata moc obliczeniową, przestrzeń na serwerach, bazy danych i dziesiątki innych usług niezbędnych do działania aplikacji i stron internetowych. Zamiast budować własne, drogie serwerownie, firmy wolą korzystać z gotowej infrastruktury Amazona.
Pomimo wystąpienia awarii, wiele serwisów funkcjonuje bez zakłóceń. Dotyczy to m.in. usług Google oraz platform należących do Meta, takich jak Facebook i Instagram. Elon Musk, właściciel X-a (dawny Twitter) zapewnił, że jego serwis również działa normalnie.
Kto pociągnął za wtyczkę? Oto winowajca
Skala tej zależności jest trudna do wyobrażenia. Z usług AWS korzystają zarówno małe startupy, jak i globalne korporacje, banki, rządy czy serwisy streamingowe. Gdy więc dochodzi do awarii w jednym z kluczowych centrów danych AWS – a wszystko wskazuje, że problemy dotyczyły głównie regionu europejskiego – następuje efekt domina. Usługi, które na co dzień uznajemy za pewnik, nagle znikają lub działają z ogromnymi opóźnieniami.
Dzisiejsza awaria brutalnie obnażyła ryzyko związane z centralizacją infrastruktury internetowej. Rynek chmury obliczeniowej jest zdominowany przez zaledwie trzech graczy: AWS, Microsoft Azure i Google Cloud. Taka koncentracja, choć wygodna i efektywna kosztowo dla biznesu, tworzy jednocześnie strategiczne, pojedyncze punkty awarii (SPOF – Single Point of Failure). Kiedy jeden z tych filarów się chwieje, trzęsie się cały cyfrowy świat.
Choć awarie tej skali nie zdarzają się często, każda z nich na nowo rozpoczyna dyskusję o dywersyfikacji infrastruktury i ryzyku polegania na jednym dostawcy. Specjaliści techniczni firmy intensywnie pracują nad przywróceniem pełnej sprawności systemu, a nowe informacje są publikowane w krótkich odstępach czasu.